#include <winpr/config.h>#include <winpr/assert.h>#include <errno.h>#include <wctype.h>#include <winpr/crt.h>#include <winpr/error.h>#include <winpr/print.h>#include "unicode.h"#include "../log.h"Macros | |
| #define | MIN(a, b) (a) < (b) ? (a) : (b) |
| #define | TAG WINPR_TAG("unicode") |
Functions | |
| static int | MultiByteToWideChar (UINT CodePage, DWORD dwFlags, LPCSTR lpMultiByteStr, int cbMultiByte, LPWSTR lpWideCharStr, int cchWideChar) |
| static int | WideCharToMultiByte (UINT CodePage, DWORD dwFlags, LPCWSTR lpWideCharStr, int cchWideChar, LPSTR lpMultiByteStr, int cbMultiByte, LPCSTR lpDefaultChar, LPBOOL lpUsedDefaultChar) |
| const WCHAR * | ByteSwapUnicode (WCHAR *wstr, size_t length) |
| SSIZE_T | ConvertWCharToUtf8 (const WCHAR *wstr, char *str, size_t len) |
| Converts form UTF-16 to UTF-8. More... | |
| SSIZE_T | ConvertWCharNToUtf8 (const WCHAR *wstr, size_t wlen, char *str, size_t len) |
| Converts form UTF-16 to UTF-8. More... | |
| SSIZE_T | ConvertMszWCharNToUtf8 (const WCHAR *wstr, size_t wlen, char *str, size_t len) |
| Converts multistrings form UTF-16 to UTF-8. More... | |
| SSIZE_T | ConvertUtf8ToWChar (const char *str, WCHAR *wstr, size_t wlen) |
| Converts form UTF-8 to UTF-16. More... | |
| SSIZE_T | ConvertUtf8NToWChar (const char *str, size_t len, WCHAR *wstr, size_t wlen) |
| Converts form UTF-8 to UTF-16. More... | |
| SSIZE_T | ConvertMszUtf8NToWChar (const char *str, size_t len, WCHAR *wstr, size_t wlen) |
| Converts multistrings form UTF-8 to UTF-16. More... | |
| char * | ConvertWCharToUtf8Alloc (const WCHAR *wstr, size_t *pUtfCharLength) |
| Converts form UTF-16 to UTF-8, returns an allocated string. More... | |
| char * | ConvertWCharNToUtf8Alloc (const WCHAR *wstr, size_t wlen, size_t *pUtfCharLength) |
| Converts form UTF-16 to UTF-8, returns an allocated string. More... | |
| char * | ConvertMszWCharNToUtf8Alloc (const WCHAR *wstr, size_t wlen, size_t *pUtfCharLength) |
| Converts multistring form UTF-16 to UTF-8, returns an allocated string. More... | |
| WCHAR * | ConvertUtf8ToWCharAlloc (const char *str, size_t *pSize) |
| Converts form UTF-8 to UTF-16, returns an allocated string. More... | |
| WCHAR * | ConvertUtf8NToWCharAlloc (const char *str, size_t len, size_t *pSize) |
| Converts form UTF-8 to UTF-16, returns an allocated string. More... | |
| WCHAR * | ConvertMszUtf8NToWCharAlloc (const char *str, size_t len, size_t *pSize) |
| Converts multistring form UTF-8 to UTF-16, returns an allocated string. More... | |
Macro Definition Documentation
◆ MIN
| #define MIN | ( | a, | |
| b | |||
| ) | (a) < (b) ? (a) : (b) |
WinPR: Windows Portable Runtime Unicode Conversion (CRT)
Copyright 2012 Marc-Andre Moreau marcandre.moreau@gmail.com Copyright 2022 Armin Novak anovak@thincast.com Copyright 2022 Thincast Technologies GmbH
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
◆ TAG
| #define TAG WINPR_TAG("unicode") |
Function Documentation
◆ ByteSwapUnicode()
| const WCHAR* ByteSwapUnicode | ( | WCHAR * | wstr, |
| size_t | length | ||
| ) |
ConvertToUnicode is a convenience wrapper for MultiByteToWideChar:
If the lpWideCharStr parameter for the converted string points to NULL or if the cchWideChar parameter is set to 0 this function will automatically allocate the required memory which is guaranteed to be null-terminated after the conversion, even if the source c string isn't.
If the cbMultiByte parameter is set to -1 the passed lpMultiByteStr must be null-terminated and the required length for the converted string will be calculated accordingly. ConvertFromUnicode is a convenience wrapper for WideCharToMultiByte:
If the lpMultiByteStr parameter for the converted string points to NULL or if the cbMultiByte parameter is set to 0 this function will automatically allocate the required memory which is guaranteed to be null-terminated after the conversion, even if the source unicode string isn't.
If the cchWideChar parameter is set to -1 the passed lpWideCharStr must be null-terminated and the required length for the converted string will be calculated accordingly. Swap Unicode byte order (UTF16LE <-> UTF16BE)


◆ ConvertMszUtf8NToWChar()
| SSIZE_T ConvertMszUtf8NToWChar | ( | const char * | str, |
| size_t | len, | ||
| WCHAR * | wstr, | ||
| size_t | wlen | ||
| ) |
Converts multistrings form UTF-8 to UTF-16.
The function does string conversions of any input string of len characters. Any character in the buffer (incuding any '\0') is converted.
Supplying wlen = 0 will return the required size of the buffer in characters.
- Warning
- Supplying a buffer length smaller than required will result in platform dependent (=undefined) behaviour!
- Parameters
-
str A CHAR string of len length len The (buffer) length in characters of str wstr A pointer to the result WCHAR string wlen The length in WCHAR characters of the result buffer
- Returns
- the size of the converted string in WCHAR characters (including any '\0'), or -1 for failure

◆ ConvertMszUtf8NToWCharAlloc()
| WCHAR* ConvertMszUtf8NToWCharAlloc | ( | const char * | str, |
| size_t | len, | ||
| size_t * | pSize | ||
| ) |
Converts multistring form UTF-8 to UTF-16, returns an allocated string.
The function does string conversions of any input string of len characters. Any character in the buffer (incuding any '\0') is converted.
- Parameters
-
str A CHAR string of len byte length len The (buffer) length in characters of str pSize Ignored if NULL, otherwise receives the length of the result string in characters (including any '\0' character)
- Returns
- An allocated double zero terminated UTF-16 string or NULL in case of failure.


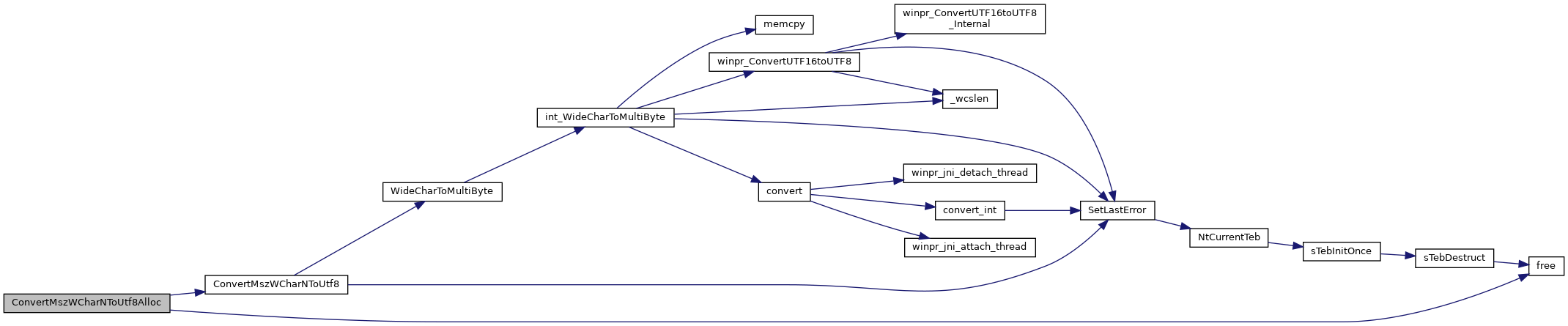
◆ ConvertMszWCharNToUtf8()
| SSIZE_T ConvertMszWCharNToUtf8 | ( | const WCHAR * | wstr, |
| size_t | wlen, | ||
| char * | str, | ||
| size_t | len | ||
| ) |
Converts multistrings form UTF-16 to UTF-8.
The function does string conversions of any input string of wlen characters. Any character in the buffer (incuding any '\0') is converted.
Supplying len = 0 will return the required size of the buffer in characters.
- Warning
- Supplying a buffer length smaller than required will result in platform dependent (=undefined) behaviour!
- Parameters
-
wstr A WCHAR string of wlen length wlen The (buffer) length in characters of wstr str A pointer to the result string len The length in characters of the result buffer
- Returns
- the size of the converted string in CHAR characters (including any '\0'), or -1 for failure

◆ ConvertMszWCharNToUtf8Alloc()
| char* ConvertMszWCharNToUtf8Alloc | ( | const WCHAR * | wstr, |
| size_t | wlen, | ||
| size_t * | pSize | ||
| ) |
Converts multistring form UTF-16 to UTF-8, returns an allocated string.
The function does string conversions of any input string of len characters. Any character in the buffer (incuding any '\0') is converted.
- Parameters
-
wstr A WCHAR string of len character length wlen The (buffer) length in characters of str pSize Ignored if NULL, otherwise receives the length of the result string in characters (including any '\0' character)
- Returns
- An allocated double zero terminated UTF-8 string or NULL in case of failure.

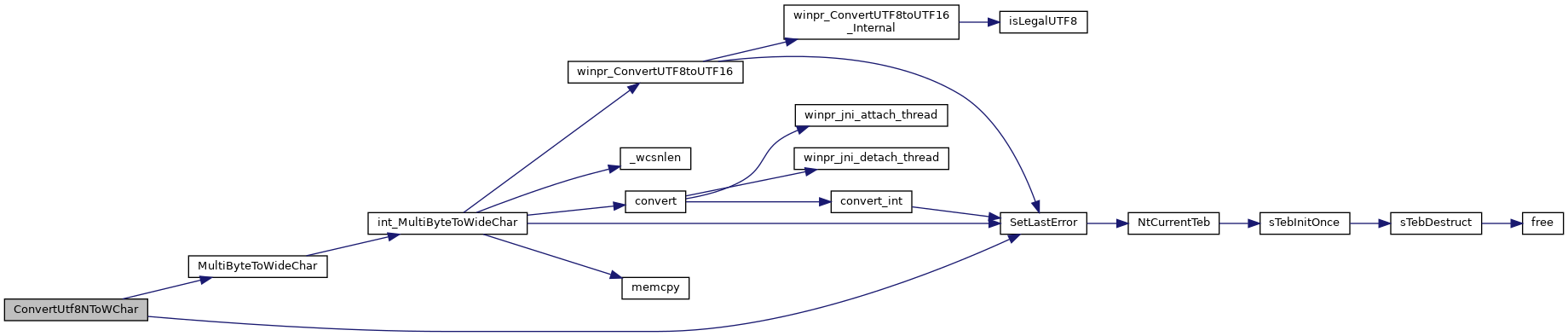
◆ ConvertUtf8NToWChar()
| SSIZE_T ConvertUtf8NToWChar | ( | const char * | str, |
| size_t | len, | ||
| WCHAR * | wstr, | ||
| size_t | wlen | ||
| ) |
Converts form UTF-8 to UTF-16.
The function does string conversions of any input string of len (or less) characters until it reaches the first '\0'.
Supplying wlen = 0 will return the required size of the buffer in characters.
- Warning
- Supplying a buffer length smaller than required will result in platform dependent (=undefined) behaviour!
- Parameters
-
str A CHAR string of len length len The (buffer) length in characters of str wstr A pointer to the result WCHAR string wlen The length in WCHAR characters of the result buffer
- Returns
- the size of the converted string in WCHAR characters (wcslen), or -1 for failure
◆ ConvertUtf8NToWCharAlloc()
| WCHAR* ConvertUtf8NToWCharAlloc | ( | const char * | str, |
| size_t | len, | ||
| size_t * | pSize | ||
| ) |
Converts form UTF-8 to UTF-16, returns an allocated string.
The function does string conversions of any input string of len (or less) characters until it reaches the first '\0'.
- Parameters
-
str A CHAR string of len length len The (buffer) length in characters of str pSize Ignored if NULL, otherwise receives the length of the result string in characters (wcslen)
- Returns
- An allocated zero terminated UTF-16 string or NULL in case of failure.

◆ ConvertUtf8ToWChar()
| SSIZE_T ConvertUtf8ToWChar | ( | const char * | str, |
| WCHAR * | wstr, | ||
| size_t | wlen | ||
| ) |
Converts form UTF-8 to UTF-16.
The function does string conversions of any '\0' terminated input string
Supplying wlen = 0 will return the required size of the buffer in characters.
- Warning
- Supplying a buffer length smaller than required will result in platform dependent (=undefined) behaviour!
- Parameters
-
str A '\0' terminated CHAR string, may be NULL wstr A pointer to the result WCHAR string wlen The length in WCHAR characters of the result buffer
- Returns
- the size of the converted string in WCHAR characters (wcslen), or -1 for failure

◆ ConvertUtf8ToWCharAlloc()
| WCHAR* ConvertUtf8ToWCharAlloc | ( | const char * | str, |
| size_t * | pSize | ||
| ) |
Converts form UTF-8 to UTF-16, returns an allocated string.
The function does string conversions of any '\0' terminated input string
- Parameters
-
str A '\0' terminated CHAR string, may be NULL pSize Ignored if NULL, otherwise receives the length of the result string in characters (wcslen)
- Returns
- An allocated zero terminated UTF-16 string or NULL in case of failure.

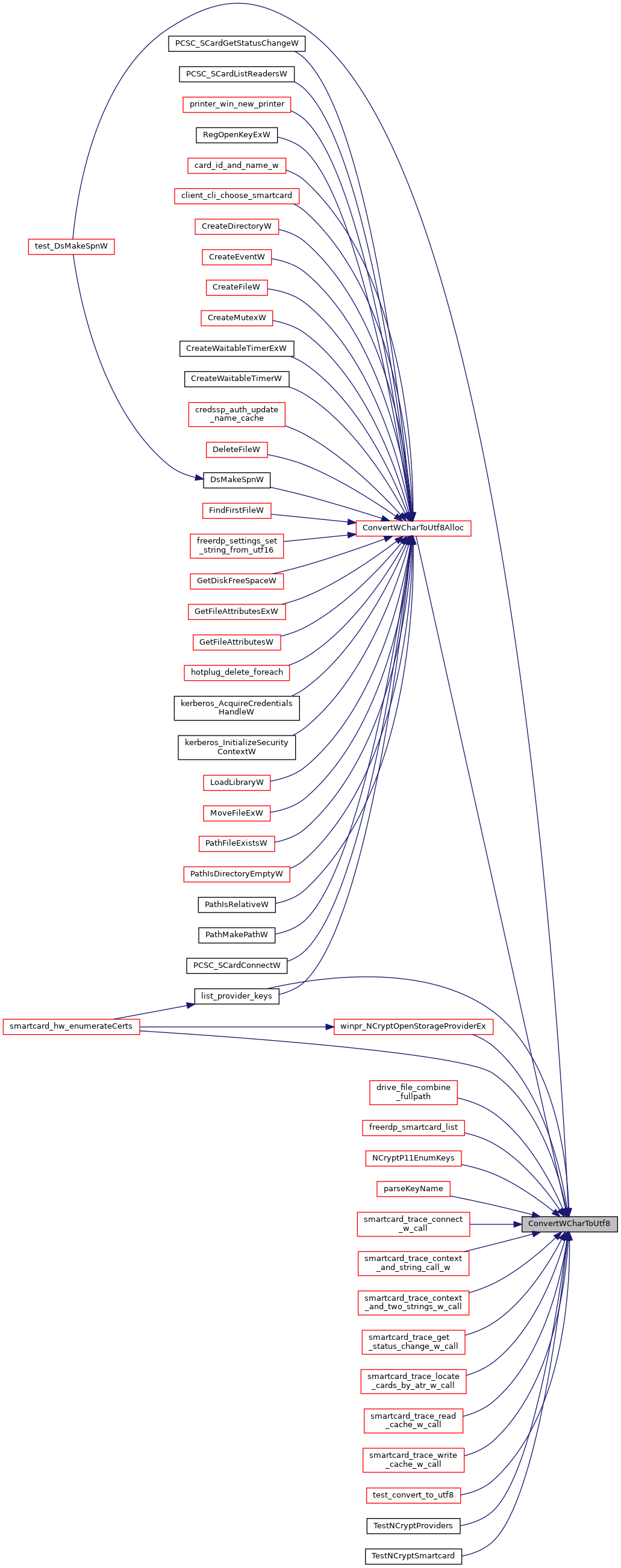
◆ ConvertWCharNToUtf8()
| SSIZE_T ConvertWCharNToUtf8 | ( | const WCHAR * | wstr, |
| size_t | wlen, | ||
| char * | str, | ||
| size_t | len | ||
| ) |
Converts form UTF-16 to UTF-8.
The function does string conversions of any input string of wlen (or less) characters until it reaches the first '\0'.
Supplying len = 0 will return the required size of the buffer in characters.
- Warning
- Supplying a buffer length smaller than required will result in platform dependent (=undefined) behaviour!
- Parameters
-
wstr A WCHAR string of wlen length wlen The (buffer) length in characters of wstr str A pointer to the result string len The length in characters of the result buffer
- Returns
- the size of the converted string in char (strlen), or -1 for failure
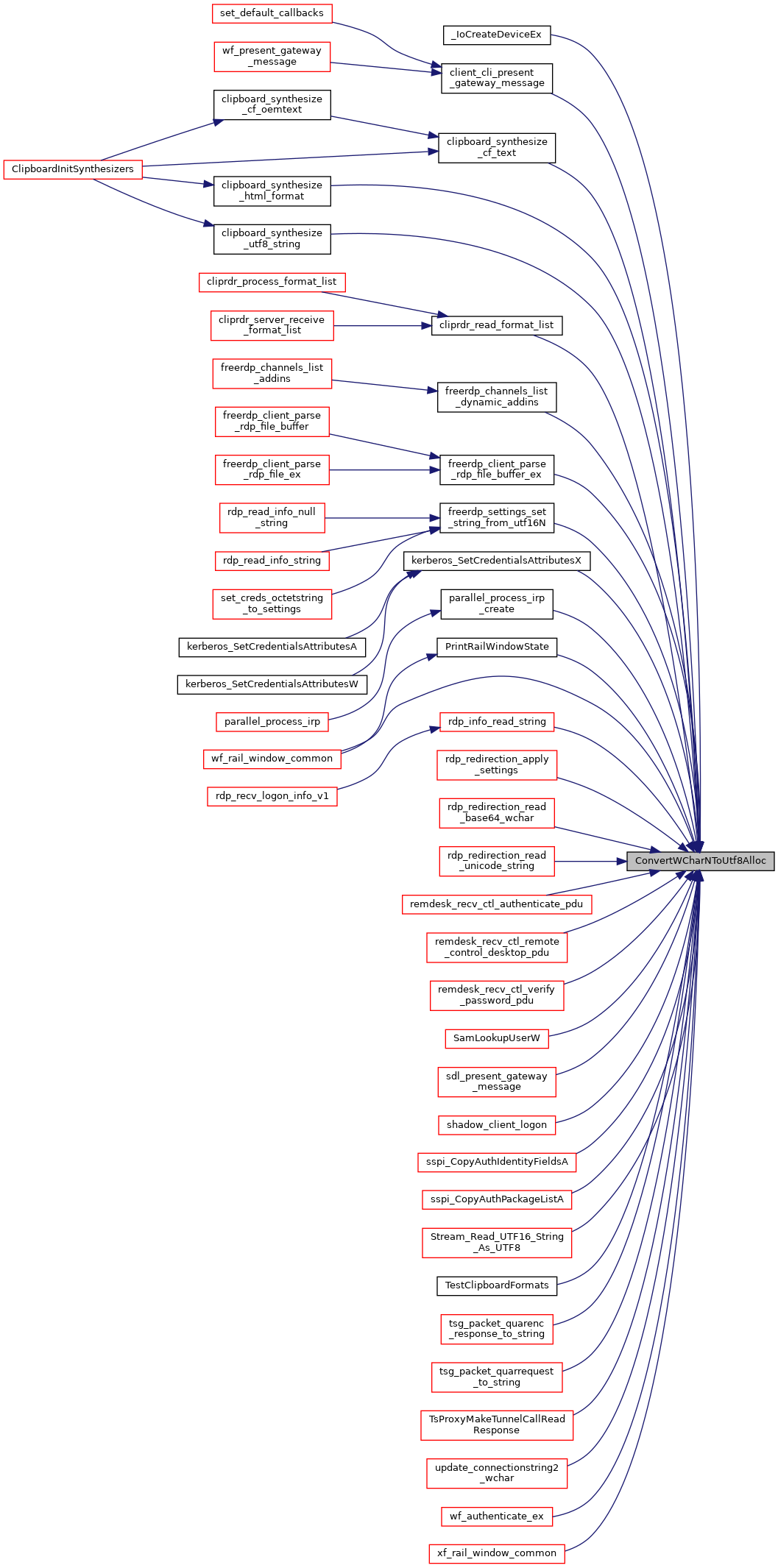
◆ ConvertWCharNToUtf8Alloc()
| char* ConvertWCharNToUtf8Alloc | ( | const WCHAR * | wstr, |
| size_t | wlen, | ||
| size_t * | pSize | ||
| ) |
Converts form UTF-16 to UTF-8, returns an allocated string.
The function does string conversions of any input string of wlen (or less) characters until it reaches the first '\0'.
- Parameters
-
wstr A WCHAR string of wlen length wlen The (buffer) length in characters of wstr pSize Ignored if NULL, otherwise receives the length of the result string in characters (strlen)
- Returns
- An allocated zero terminated UTF-8 string or NULL in case of failure.
◆ ConvertWCharToUtf8()
| SSIZE_T ConvertWCharToUtf8 | ( | const WCHAR * | wstr, |
| char * | str, | ||
| size_t | len | ||
| ) |
Converts form UTF-16 to UTF-8.
The function does string conversions of any '\0' terminated input string
Supplying len = 0 will return the required size of the buffer in characters.
- Warning
- Supplying a buffer length smaller than required will result in platform dependent (=undefined) behaviour!
- Parameters
-
wstr A '\0' terminated WCHAR string, may be NULL str A pointer to the result string len The length in characters of the result buffer
- Returns
- the size of the converted string in char (strlen), or -1 for failure

◆ ConvertWCharToUtf8Alloc()
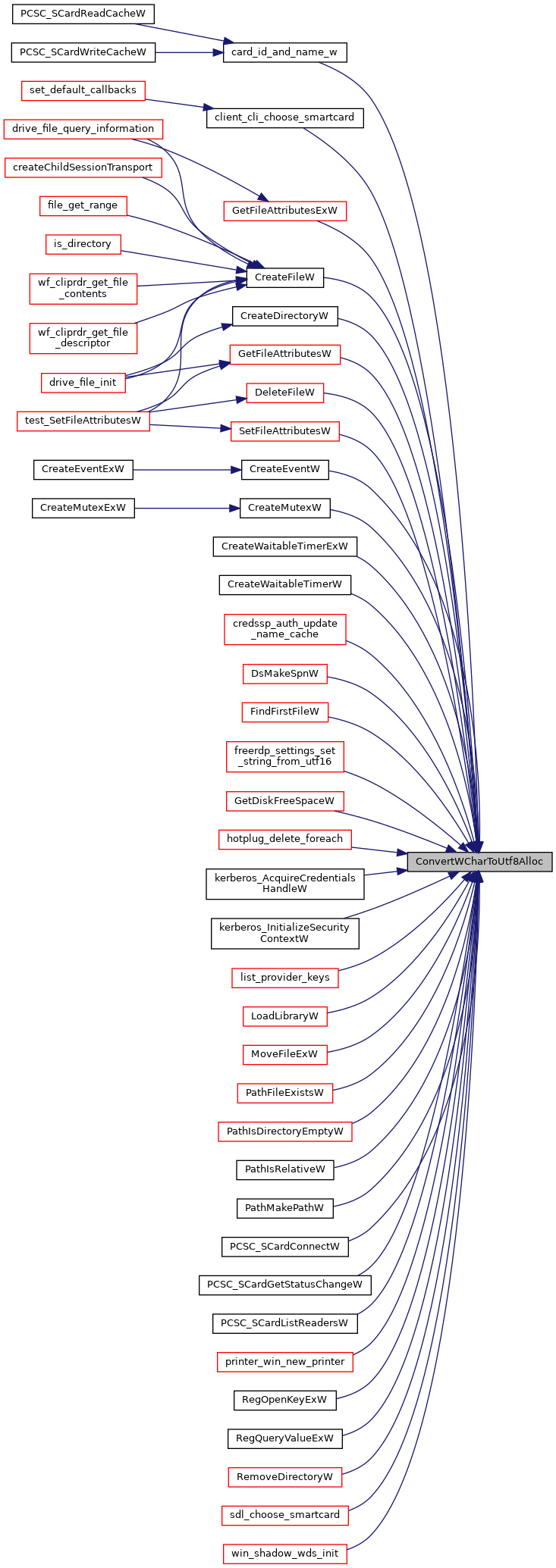
| char* ConvertWCharToUtf8Alloc | ( | const WCHAR * | wstr, |
| size_t * | pSize | ||
| ) |
Converts form UTF-16 to UTF-8, returns an allocated string.
The function does string conversions of any '\0' terminated input string
- Parameters
-
wstr A '\0' terminated WCHAR string, may be NULL pSize Ignored if NULL, otherwise receives the length of the result string in characters (strlen)
- Returns
- An allocated zero terminated UTF-8 string or NULL in case of failure.

◆ MultiByteToWideChar()
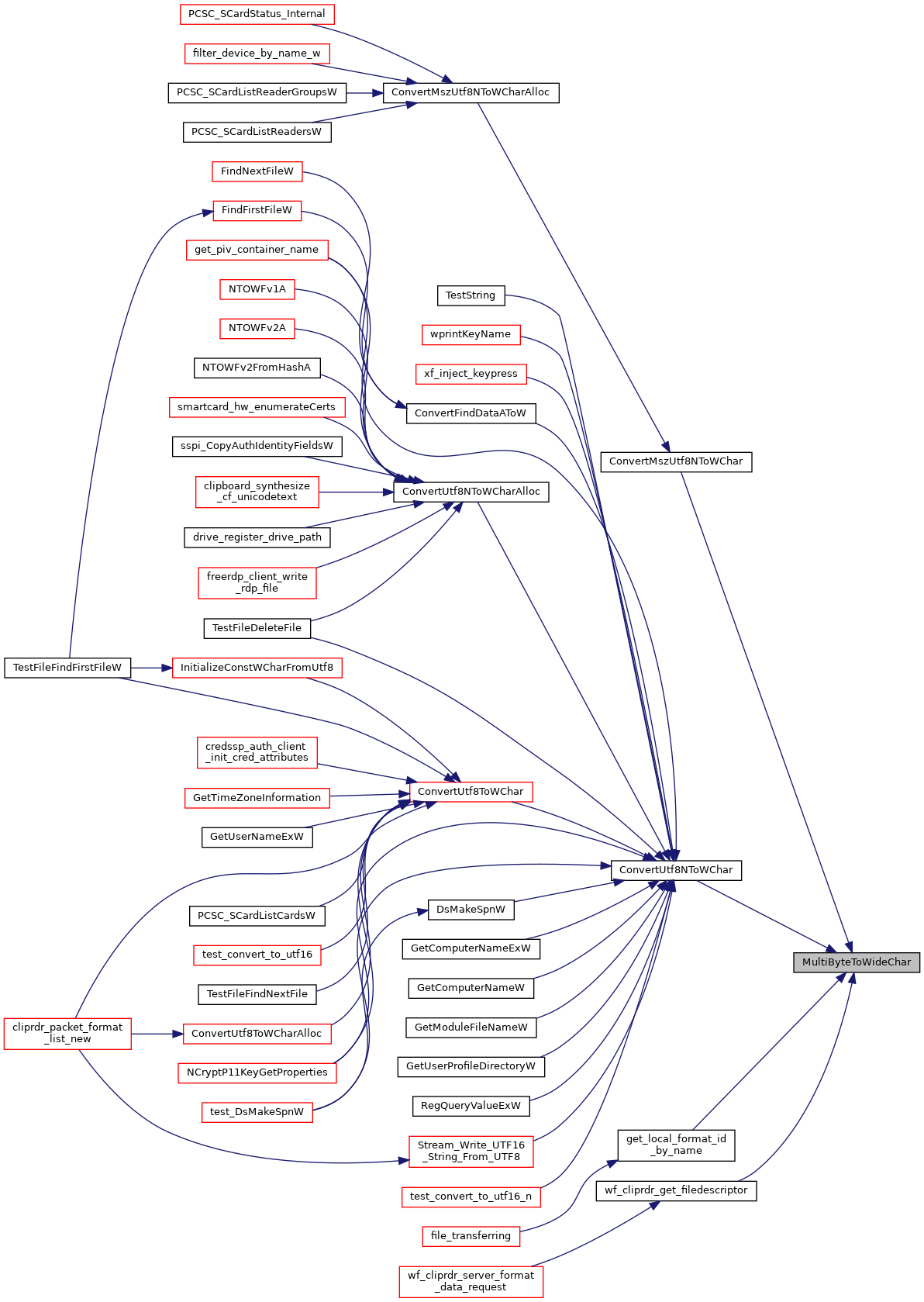
|
static |
Notes on cross-platform Unicode portability:
Unicode has many possible Unicode Transformation Format (UTF) encodings, where some of the most commonly used are UTF-8, UTF-16 and sometimes UTF-32.
The number in the UTF encoding name (8, 16, 32) refers to the number of bits per code unit. A code unit is the minimal bit combination that can represent a unit of encoded text in the given encoding. For instance, UTF-8 encodes the English alphabet using 8 bits (or one byte) each, just like in ASCII.
However, the total number of code points (values in the Unicode codespace) only fits completely within 32 bits. This means that for UTF-8 and UTF-16, more than one code unit may be required to fully encode a specific value. UTF-8 and UTF-16 are variable-width encodings, while UTF-32 is fixed-width.
UTF-8 has the advantage of being backwards compatible with ASCII, and is one of the most commonly used Unicode encoding.
UTF-16 is used everywhere in the Windows API. The strategy employed by Microsoft to provide backwards compatibility in their API was to create an ANSI and a Unicode version of the same function, ending with A (ANSI) and W (Wide character, or UTF-16 Unicode). In headers, the original function name is replaced by a macro that defines to either the ANSI or Unicode version based on the definition of the _UNICODE macro.
UTF-32 has the advantage of being fixed width, but wastes a lot of space for English text (4x more than UTF-8, 2x more than UTF-16).
In C, wide character strings are often defined with the wchar_t type. Many functions are provided to deal with those wide character strings, such as wcslen (strlen equivalent) or wprintf (printf equivalent).
This may lead to some confusion, since many of these functions exist on both Windows and Linux, but they are not the same!
This sample hello world is a good example:
#include <wchar.h>
wchar_t hello[] = L"Hello, World!\n";
int main(int argc, char** argv) { wprintf(hello); wprintf(L"sizeof(wchar_t): %d\n", sizeof(wchar_t)); return 0; }
There is a reason why the sample prints the size of the wchar_t type: On Windows, wchar_t is two bytes (UTF-16), while on most other systems it is 4 bytes (UTF-32). This means that if you write code on Windows, use L"" to define a string which is meant to be UTF-16 and not UTF-32, you will have a little surprise when trying to port your code to Linux.
Since the Windows API uses UTF-16, not UTF-32, WinPR defines the WCHAR type to always be 2-bytes long and uses it instead of wchar_t. Do not ever use wchar_t with WinPR unless you know what you are doing.
As for L"", it is unfortunately unusable in a portable way, unless a special option is passed to GCC to define wchar_t as being two bytes. For string constants that must be UTF-16, it is a pain, but they can be defined in a portable way like this:
WCHAR hello[] = { 'H','e','l','l','o','\0' };
Such strings cannot be passed to native functions like wcslen(), which may expect a different wchar_t size. For this reason, WinPR provides _wcslen, which expects UTF-16 WCHAR strings on all platforms.
Conversion to Unicode (UTF-16) MultiByteToWideChar: http://msdn.microsoft.com/en-us/library/windows/desktop/dd319072/
cbMultiByte is an input size in bytes (BYTE) cchWideChar is an output size in wide characters (WCHAR)
Null-terminated UTF-8 strings:
cchWideChar cannot be assumed to be cbMultiByte since UTF-8 is variable-width!
Instead, obtain the required cchWideChar output size like this: cchWideChar = MultiByteToWideChar(CP_UTF8, 0, (LPCSTR) lpMultiByteStr, -1, NULL, 0);
A value of -1 for cbMultiByte indicates that the input string is null-terminated, and the null terminator will be processed. The size returned by MultiByteToWideChar will therefore include the null terminator. Equivalent behavior can be obtained by computing the length in bytes of the input buffer, including the null terminator:
cbMultiByte = strlen((char*) lpMultiByteStr) + 1;
An output buffer of the proper size can then be allocated:
lpWideCharStr = (LPWSTR) malloc(cchWideChar * sizeof(WCHAR));
Since cchWideChar is an output size in wide characters, the actual buffer size is: (cchWideChar * sizeof(WCHAR)) or (cchWideChar * 2)
Finally, perform the conversion:
cchWideChar = MultiByteToWideChar(CP_UTF8, 0, (LPCSTR) lpMultiByteStr, -1, lpWideCharStr, cchWideChar);
The value returned by MultiByteToWideChar corresponds to the number of wide characters written to the output buffer, and should match the value obtained on the first call to MultiByteToWideChar.

◆ WideCharToMultiByte()
|
static |
Conversion from Unicode (UTF-16) WideCharToMultiByte: http://msdn.microsoft.com/en-us/library/windows/desktop/dd374130/
cchWideChar is an input size in wide characters (WCHAR) cbMultiByte is an output size in bytes (BYTE)
Null-terminated UTF-16 strings:
cbMultiByte cannot be assumed to be cchWideChar since UTF-8 is variable-width!
Instead, obtain the required cbMultiByte output size like this: cbMultiByte = WideCharToMultiByte(CP_UTF8, 0, (LPCWSTR) lpWideCharStr, -1, NULL, 0, NULL, NULL);
A value of -1 for cbMultiByte indicates that the input string is null-terminated, and the null terminator will be processed. The size returned by WideCharToMultiByte will therefore include the null terminator. Equivalent behavior can be obtained by computing the length in bytes of the input buffer, including the null terminator:
cchWideChar = _wcslen((WCHAR*) lpWideCharStr) + 1;
An output buffer of the proper size can then be allocated: lpMultiByteStr = (LPSTR) malloc(cbMultiByte);
Since cbMultiByte is an output size in bytes, it is the same as the buffer size
Finally, perform the conversion:
cbMultiByte = WideCharToMultiByte(CP_UTF8, 0, (LPCWSTR) lpWideCharStr, -1, lpMultiByteStr, cbMultiByte, NULL, NULL);
The value returned by WideCharToMultiByte corresponds to the number of bytes written to the output buffer, and should match the value obtained on the first call to WideCharToMultiByte.